12月4-5日Web上で開催された、林業経済学会2021年秋季大会発表会で、標記タイトルで報告しました。
12月4-5日Web上で開催された、林業経済学会2021年秋季大会発表会で、標記タイトルで報告しました。
(報告の趣旨と構成)
 「森林・林業基本計画は、 グローバルな 森林 ガバナンス強化の中で FAO などにより提唱されている National ForestryProgmamm
e の我が国版であるとされている 。 グローバルな位置づけから森林 ・ 林業基本計画を評価する場合、策定プロセスの 関係者の参画過程が重要な評価要素になる
。」ということで、グローバルな視野から参画過程の分析の重要性をイントロで紹介
「森林・林業基本計画は、 グローバルな 森林 ガバナンス強化の中で FAO などにより提唱されている National ForestryProgmamm
e の我が国版であるとされている 。 グローバルな位置づけから森林 ・ 林業基本計画を評価する場合、策定プロセスの 関係者の参画過程が重要な評価要素になる
。」ということで、グローバルな視野から参画過程の分析の重要性をイントロで紹介
少し前のことになりますが、森林林業基本法が改正された次の年のカナダのカナナキスで開催された、G8サミットで合意された二つの文書の一節を引用しました(右の図)
 Action Programme on Forests - Final Report Kananaskis Summit(2002)
Action Programme on Forests - Final Report Kananaskis Summit(2002)
G8 ACTION PROGRAMME ON FORESTS – BACKGROUNDERS
そして、構成は左の通り
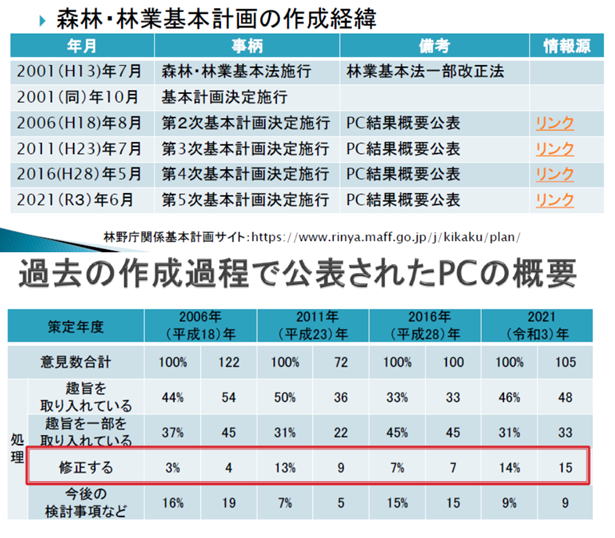 2006年から4回にわたる基本計画の策定過程で提出された400件ほどのパブコメ(右の図)がネット上に公開されています。
2006年から4回にわたる基本計画の策定過程で提出された400件ほどのパブコメ(右の図)がネット上に公開されています。
これを分析対象としました。
(セッションごとのパブコメ提出動向)
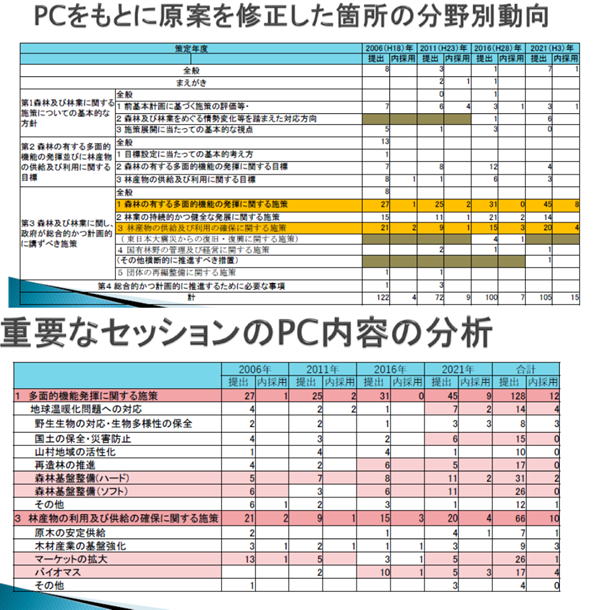 基本計画は、森林林業基本法で法律で、「① 森林及び林業に関する施策についての基本的な方針、② 森林の有する多面的機能の発揮並びに林産物の供給及び利用に関する目標、③ 森林及び林業に関し、政府が総合的かつ計画的に講ずべき施策、④ 前三号に掲げるもののほか、森林及び林業に関する施策を総合的かつ計画的に推進するために必要な事項の構成」と4つの構成とするよう規定されており、サブセッションもおよそ同じような構成になっています。
基本計画は、森林林業基本法で法律で、「① 森林及び林業に関する施策についての基本的な方針、② 森林の有する多面的機能の発揮並びに林産物の供給及び利用に関する目標、③ 森林及び林業に関し、政府が総合的かつ計画的に講ずべき施策、④ 前三号に掲げるもののほか、森林及び林業に関する施策を総合的かつ計画的に推進するために必要な事項の構成」と4つの構成とするよう規定されており、サブセッションもおよそ同じような構成になっています。
それごとの、パブコメ提出状況は?
左上の図です。
全体に「第3 森林及び林業に関し、政府が総合的かつ計画的に講ずべき施策」という具体的施策に応じたセッションの中の、1 森林の有する多面的機能の発揮に関する施策、3
林産物の供給及び利用の確保に関する施策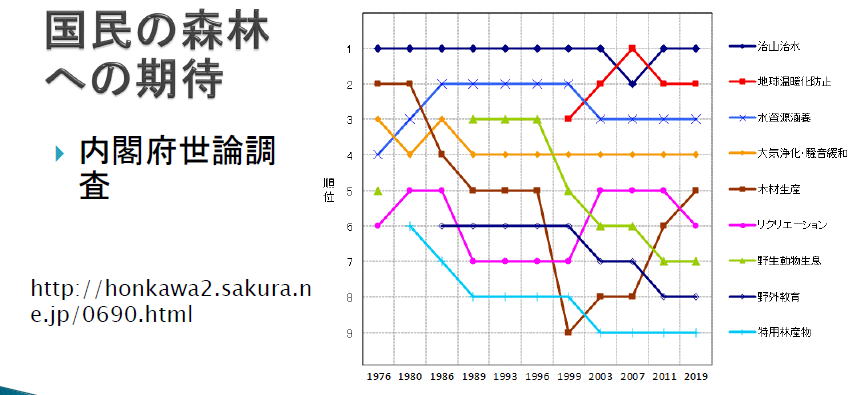 という部分に提出数が多く、さらに左下の図。
という部分に提出数が多く、さらに左下の図。
それらの中で、近年の1の中の「地球温暖化問題への対応」、「国土保全・災害防止」のサブセッションに、また3の「マーケットの拡大」に対するパグコメ提出が少し多くなってきていることがわかります。
これらのことは、右の図の国民の関心事項の調査結果との関係性など、一定程度説明しています。
(計量的テキスト分析)
計量的テキスト分析とは、「人の言葉として表現されたテキストデータから、情報を可視化。 個人の経験や勘に左右されない安定した情報を提供することによって、目的に応じた知見を掘り起こし、新たな発想、思
わぬ発見につながる提案を実現。」
前述のセッションごとの分析は、時系列に分析する場合、毎回同じセッションで構成されるのか?という、不安定感があります。時間軸がもっと長くなった場合不安定(セッション構成の変化)になります。そこで、テキストをそのまま取り出し、どんな文言が多いのか、また、どんな文言とどんな文言が一緒に使われるケースがおおいのか?
 先行研究では、2時点の2年分の新聞記事をすべて分析対象とした、人々の「森林」に対する認識の変化に関する研究ー―1980 年代後半と 2000 年代後半の言説空間の比較から(片野 洋平 2012 環境情報科学論文集/Vol.26 (第 26 回環境情報科学学術研究論文発表会) 書誌というのがあります。
先行研究では、2時点の2年分の新聞記事をすべて分析対象とした、人々の「森林」に対する認識の変化に関する研究ー―1980 年代後半と 2000 年代後半の言説空間の比較から(片野 洋平 2012 環境情報科学論文集/Vol.26 (第 26 回環境情報科学学術研究論文発表会) 書誌というのがあります。
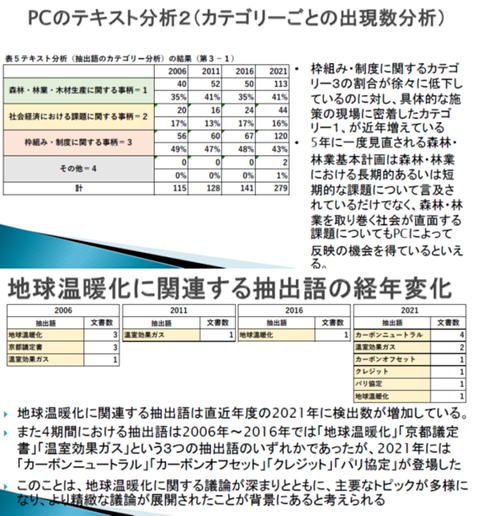
左の図が今回のテキスト分析の結果の一部です。
上記のセッションのうち、「第3の1. 森林の有する多面的機能の発揮に関する施策」の寄せられたパブコメの内容を分析した結果です。
上の図が、パブコメに記載している名詞と一定の言語の連鎖(あわせて「抽出語」)を、三つのカテゴリーすなわち、1森林・林業・木材産業に関する事柄、2社会経済に関する課題、3枠組み制度に関する事例に分けてその頻度を分析したもの。
 下の図は地球温暖化に関連する抽出語の経年変化です。
下の図は地球温暖化に関連する抽出語の経年変化です。
記載しているように、「森林・林業を取り巻く社会が直面する課題についてパブコメによって反映の機会を得ている」ことがわかるところまでは、いったのでないか、というのが今回の分析結果です。
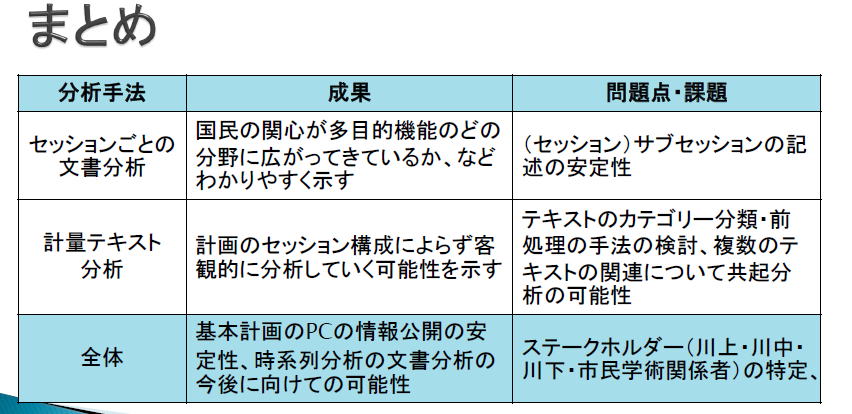
右の図の報告の「まとめ」にもあるように、また、質疑の中で指摘されているように、今後の課題がたくさんの報告でもありました。
(質疑)
| 問 |
答 |
| 質問者A |
|
1. テキストマイニングを用いた政策資料の研究はたくさんありますが、どのような研究群を参照されたのでしょうか?
|
日本語のテキストマイニングの先行研究で参照したのは資料17ページにある
人々の「森林」に対する認識の変化に関する研究ー―1980 年代後半と 2000 年代後半の言説空間の比較から(片野 洋平 2012 環境情報科学論文集/Vol.26 (第 26 回環境情報科学学術研究論文発表会) 書誌
林業の労働災害分析へのテキストマイニングの適用可能性(猪俣 雄太他 2020 森林利用学会誌 /35 巻(2020) 4 号 書誌)
です
政策論とテキストマイニングでネット上でひろったものですが、ほかに参照すべきものがあれば、ご教示いただけますか? |
| グローバルなガバナンス比較への貢献を目指されたということは、海外のいくつかの文献を参照されたのでしょうか? |
前書きでグローバリティについてふれたのは、資料4ページにあるように、日本政府が基本計画を、National Forest Programmesであると主張しているので、それなら、They
have become secure platforms for dialogue with other sectors of the economy
and well established coordinating instruments for stakeholder participation.
Successive iterations of these
参画過程の分析が重要です、というこの報告の意義を強調する文脈です |
2.当日の報告資料は見られていませんが、要旨集には方法の説明がほとんどされていませんでした。
どのようなソフトを用い、どのように形態要素分析をされたのでしょうか?
例えば、「森林」が頻出語となっていますが、「森林組合」は一つの単語として区分されるように設定されたのでしょうか?
「公共」がしばしば出ていますが、これは「地方公共団体」がぶつ切りされたものですか? |
ソフトは、資料18ページにあるように大阪大学樋氏開発KH Coder©です
先行研究も大体これを使っていると思います
おっしゃる通り、単語の前処理過程が重要ですね
単語の処理の具体的なところ、森林組合、地方公共団体に関しては以下の以下の通りです
ーーーー
作業としては、以下の手順で実施しております。
1.各年度PC公表資料(PDF)のテキスト化:Adobe社のacrobat_readerを用いて、テキストに転換(excelファイルとして出力)
2.ご変換の修正:excelに出力したテキストが正しく転換されているかを確認(元のPDFとの照らし合わせ)
3.表記ゆれの調整:例えば「スギ」「杉」「すぎ」を「スギ」に統一、「GHG」「温室効果ガス」「二酸化炭素」「温暖化ガス」などの表記を「温室効果ガス」に統一など
4.用語のリストアップ:2.3.の過程で確認された用語をリスト化
5.用語の抽出:KHCoder上でterm extractを用いて前処理を実施
6.森林林業関連用語の抽出:4.でリストアップした用語をKHcoder上で「強制抽出語リスト」に登録し、テキスト(excel)の前処理を実施。
7.抽出語リストを作成:KHcoderを用いて抽出語リストを作成
8.品詞による分類:各年度のトピックの傾向を見るために「名詞」「タグ(6.の強制抽出語)」に絞り、出現文書数順に並べ替え(文書数としたのは、一つの文章内で同じ用語が繰り返し記述されているケースが多く見られたため)
9.抽出された用語の分類:森林・林業・木材生産に関する事柄=1、社会経済における課題に関する事柄=2、枠組み・制度に関する事柄=3に分類し、集計
このような手順で実施しました。
しかし、一部強制抽出語(例えばご指摘の「森林組合」)が「森林」と「組合」に分解される一方、「森林・林業基本計画」は認識されるなどの不具合が発生し、まずは森林で認識させることとしました。ご指摘の通り、本来分解しては異なる意味を持つ用語が「森林」でカウントされてしまうことには問題があり、今後検討を進めるうえで、不具合の原因を究明し、用語として正しく認識されたものを用いて、改めて集計を行います。 |
3.今回は、単語の出現頻度の集計のみを行われたようですが、共起ネットワーク分析は行われなかったのでしょうか?
2で述べたように要素形態分析に問題があるとしても、共起ネットワーク分析がなされていればある程度文脈を類推することができますので、もし行われていればその結果が興味深く存じます。 |
ありがとうございました。重要な視点ですね
23ページ(上記「まとめ」)にありますように、今後の課題としています |
4.テキストマイニングは、大量の文章を機械的に処理できることに強みがあり、今回行われた程度の分量であれば、人力で処理できると考えられなくもありません。
その意味で、今後どのような方向にご研究を展開して行かれるのでしょうか? |
おっしゃるとおでですね
先行片野研究は、朝日新聞と読売新聞の2年間の全記事を対象に分析しています
今回の報告に至る過程は、テキストマイニングより、基本計画のパブコメの時系列分析というのが主たる問題意識でしたので、今後パブコメの分析手法を少しさらに進めてまいりたいと思います。そのツールとしてKHコーダーを一つの選択肢としてまいります
今後ともよろしくお願いします |
| 質問者B |
|
| 1)どういう意見が採用され、同意見が採用されないか、傾向は分からないでしょうか。 |
上記10ページ目にセッションごとの傾向がわかるかどうか、確認してみましたがなかなか、ご報告できるような内容には、なっておりません。
重要な視点なので、採用された内容の傾向分析など今後のテーマとしてまいりたいと思います |
| 2)個人情報保護の制約はあるでしょうが、コメントを出す人、団体について、または数について傾向は言えないでしょうか。 |
政府の公表されたデータから提出者の属性はわかりません
ただ、テキスト分析というツールで、その属性を特定していく可能性はあるかと思います
資料の23枚目(上記「まとめ」)の今後の課題「ステークホルダー(川上・川中・川下・市民学術関係者)の特定、と報告させていただきました。これも今後の課題です
|
関連資料を以下に掲載していますので、関心のある方はどうぞ
要旨、プレゼン資料
kokunai1-25 <BPPctext>